UEMM-Air: Enable UAVs to Undertake More Multi-modal Tasks
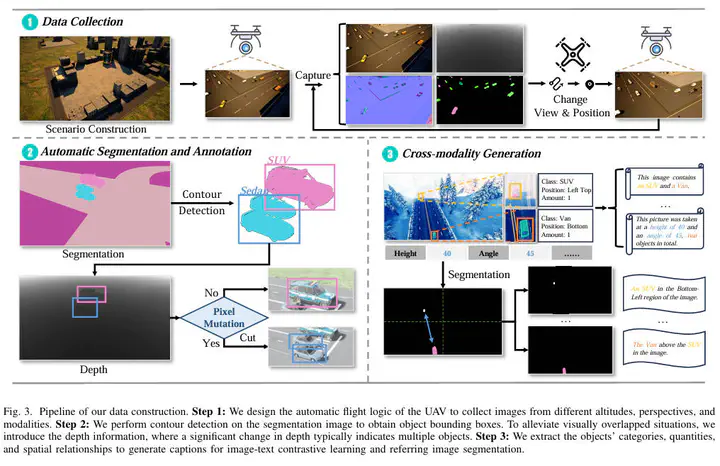 The Pipeline of data construction
The Pipeline of data constructionAbstract
The development of multi-modal Unmanned Aerial Vehicles (UAVs) environment perception systems is hindered by three critical gaps in existing datasets: (1) insufficient modalities and pixel misalignment, (2) noisy labels, and (3) limited task types. To address these gaps, we propose an automatic data construction approach and construct a multi-modal UAV-based environment perception dataset, UEMM-Air. Its synthetic nature ensures scalability, reproducibility, and rare-event coverage, making it suitable for large-scale model pre-training. Benefiting from our automated data collection and annotation pipeline, UEMM-Air encompasses 120k data pairs across 6 aligned modalities and supports 4 perception tasks, significantly exceeding existing datasets (max 60k data, 3 modalities, 2 tasks). Compared to existing synthetic datasets like SynDrone, UEMM-Air provides more accurate annotations by avoiding noisy labels from direct coordinate computation. Notably, models pre-trained on UEMM-Air achieve a 5.8% accuracy improvement compared to those utilizing other synthetic datasets, while requiring less than half the data. This benchmark establishes performance evaluation of UAV multi-modal environmental perception models, and hopefully encourages more research efforts towards enabling UAVs to undertake more multi-modal tasks. The dataset and its generation engine are openly accessible under a permissive license at https://github.com/1e12leon/UEMM-Air.