Making Large Vision Language Models to Be Good Few-Shot Learners
 The overview of approach
The overview of approachAbstract
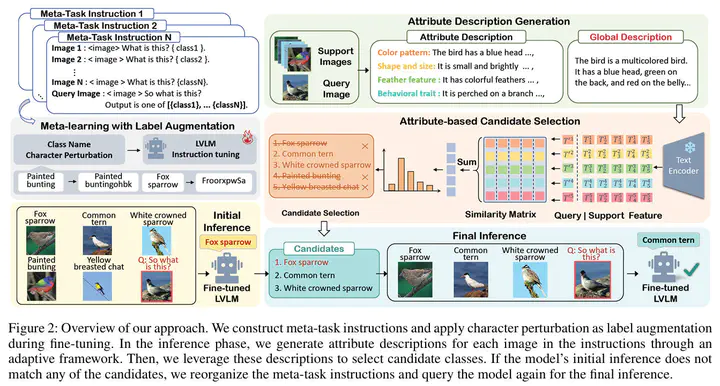
Few-shot classification (FSC) is a fundamental yet challenging task in computer vision that involves recognizing novel classes from limited data. While previous methods have focused on enhancing visual features or incorporating additional modalities, Large Vision Language Models (LVLMs) offer a promising alternative due to their rich knowledge and strong visual perception. However, LVLMs risk learning specific response formats rather than effectively extracting useful information from support data in FSC. In this paper, we investigate LVLMs’ performance in FSC and identify key issues such as insufficient learning and the presence of severe position biases. To tackle above challenges, we adopt the meta-learning strategy to teach models “learn to learn”. By constructing a rich set of meta-tasks for instruction fine-tuning, LVLMs enhance the ability to extract information from few-shot support data for classification. Additionally, we further boost LVLM’s few-shot learning capabilities through label augmentation (LA) and candidate selection (CS) in the fine-tuning and inference stages, respectively. LA is implemented via a character perturbation strategy to ensure the model focuses on support information. CS leverages attribute descriptions to filter out unreliable candidates and simplify the task. Extensive experiments demonstrate that our approach achieves superior performance on both general and fine-grained datasets. Furthermore, our candidate selection strategy has been proven beneficial for training-free LVLMs.